
The Evolution of Source Code

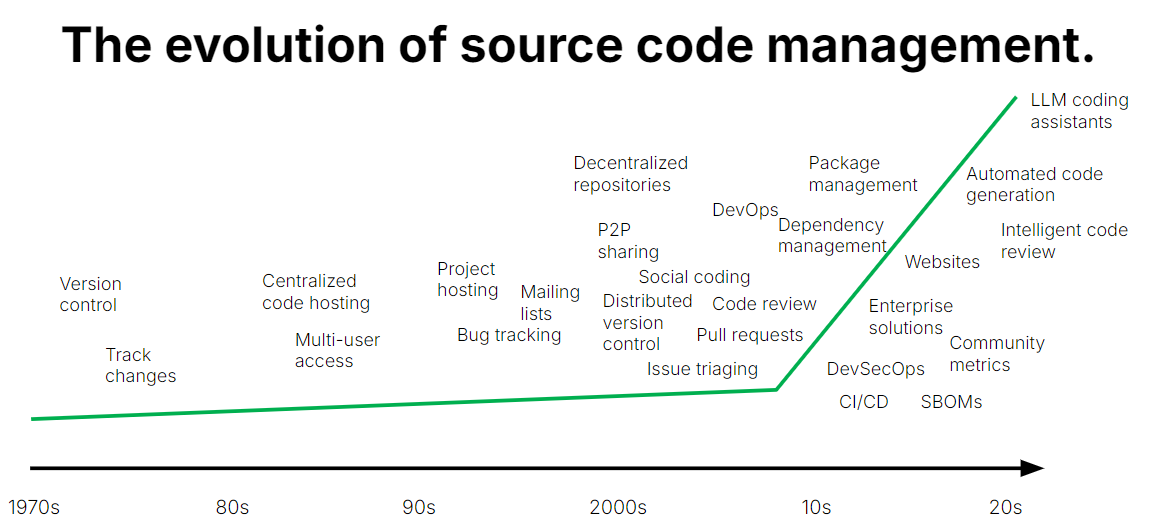
We're going back 70 years to look at how managing source code has evolved. From manually typing code printed in magazines to using sophisticated all-encompassing cloud-based providers, the journey has been fast. Has that been a good thing?
Public domain and type-in
The image at the top of this article shows a 'type-in program': computer source code printed in a magazine. In this case, manually typing the code in that document into your computer and running it will allow you to play Hex War published in the July 1986 issue of Compute!. It's hard to imagine now one developer printing code in books and another typing it into their computer to play a game, but that's how things were for several decades. In the 1950s, academics and 'hackers', created and shared code for free via magazines and books as 'public-domain' software. Whilst code collaboration was increasing, researchers at Bell Labs were finding a way to ensure that changes in source code could be tracked, allowing users to restore old versions of code and reducing the risk of overwriting their work. In 1972, the source code control system (SCCS) was released, with a public version available five years later. SCSS dominated Unix but notably lacked features that are common in modern solutions such as networking capabilities and limited branching.
Copyright and forges
In the 70s, sharing of software hit a block in the form of copyright, allowing closed source software businesses to really take off, not that this stopped the hackers, who carried on sharing software without paying licensing fees, something that led Bill Gates to write the infamous 'An Open Letter to Hobbyists'. Saving the Open movement, Richard Stallman founded the GNU project and created the copyleft licence (licenses are the subject for a whole other blog). As developers fought back, the need for better, centralised ways to manage code became more important. The revision control system (RCS) and concurrent version systems (CVS) emerged in the 80s, looking more like a modern version control system (VCS), indeed RCS is still actively maintained by GNU with the latest version released in 2022. Critically, CVS (a front-end to RCS) allows tracking over entire projects as well as advanced branching capabilities. CVS also allows multiple developers to work on projects simultaneously, with a client-server architecture that meant programmers across wider areas could share their work. Open-source and collaborative software really began to take off.
Collaboration and hosting
The 90s propelled collaborative software development with the release of Linux under Stallman's copyleft licence, the definition of the term 'open source' and the birth of the Open Source Initiative. The formalisation of the movement allowed more cohesive controls and development for necessary software collaboration features such as mailing lists for discussing feature requests and bug tracking. However, software was still being shared and collaborated on via a mishmash of different mediums, including in print, private networks of FTP sites, and online bulletin boards. So at the end of the 90s, SourceForge was founded as the first provider of a centralized location for open-source software.
Git and source code management
The open source movement and collaborative coding exploded in the 00s. As SourceForge demonstrated the potential for collaboration, other platforms for code hosting and management appeared, including GNU Savannah and Launchpad. Then, in 2005, Git was released as a distributed version control system by Linus Torvalds. Torvalds explicitly created Git to fix problems he perceived in CVS saying "if in doubt, make the exact opposite decision to CVS". Git allows developers to have a copy of their repository locally, it has snapshots of entire projects making it easier to revert changes, is fast, allows offline work, and has many other advantages. As Git was rapidly taken up by the coding community, a few developers realised its full potential as a hub for coders worldwide, and GitHub was launched in 2008 with BitBucket also launched in the same year. From that point 'source code hosting' platforms moved to 'source code management', with solutions including built-in tools for issue tracking, feature requests, and code review.
Source code monoliths
As practices (DevOps, GitOps, and all the others) have emerged over the past two decades, source code management platforms (SCMs) have tried to incorporate them all into their systems, creating monoliths that try to do everything involving source code, which we call (with our tongues in cheek), 'SourceOps'. This is very far from the simple code hosting of the first systems.
The question we've been asking ourselves is whether this is a good thing? Should a single platform have all the control over your code? Over how it is hosted and what tools you can use to manage it? When modern-day solutions include AI-powered tools for intelligent code review, issue tracking, and code generation, why are they still being shoehorned into decades-old platforms via frustrating scripts and a plethora of tokens? Don't get us wrong, we're not saying today's solutions are bad, we just think things could be more efficient.
Are you also frustrated? Join us in the source code orchestration revolution. Get in touch today.